Data Tool Decision Tree: Reduce Data Cleaning Time
- 10 minutes read - 2038 wordsMy dad likes to say that cooking is another form of creativity - part art, part science - that produces something physical, edible, and enjoyable with the chef’s unique style. Programming can be similar (minus the edible part).
To learn to cook, you can take classes or read books, but the best teacher is rolling up your sleeves and experimenting yourself. When should you choose this utensil or that? Can I substitute ingredient A for B? How does the cooking method affect taste or texture?
Many technology tools fall into the same category - the best teacher is experience. Over the last couple of weeks, I have been working on a project that needed an interesting data set for demos. Data sets I found either were too narrow/small or too large for demoing. I needed to take the larger data set and slice it into something manageable for my purposes. But which tools to use? There are many tools for working with data - various formats, command line tools, and even databases. How do I know when to choose what tool?
In this blog post, I hope to share my decision tree for choosing the right data tool for the job in hopes I can spare others some of the headaches and time lost I’ve spent getting here. :) I’m sure this content will change as I learn more, but it gives us a starting point!
The Problem
I really wanted to focus on books, and I came across a broad (and very large) set used in academic papers - the UCSD Book Graph. The problem now was that I needed to cut some of it down for demos (maybe around 10,000 books or so) to make it easy to load, query, and interact with performantly.
I downloaded the zipped JSON files and started hacking. The files are huge, so the download takes some time. The main book file alone contains 2.3 million book records! That is definitely too much for quick demos, though it would be great for other scenarios. So what is the best method to reduce the amount of data? There were two different approaches that felt appropriate for this data set - 1. reducing the number of total objects (books), 2. trimming out some (of the many) properties.
With two approaches in mind, what’s the best way to execute those? Let’s take a look at some things I tried and where I got stuck.
What I Tried
There are some pretty powerful command line tools at our disposal, so I started there. Command line tools are quick, lightweight, and can format different types of data using command options. Since this data set works with JSON data, I went straight for a tool called jq.
jq is a command line tool that is helpful for JSON data processing. Removing specific properties on JSON files is one of the things it handles well. There is even a nice (and very useful) jq playground where you can copy some JSON and test commands to view outputs or troubleshoot errors before running them on the full data set.
I removed a few fields on the main JSON file with jq, which cut down size from 9.2GB to 1.89GB. That helped a ton! Now I needed to decrease the total number of books in the file so that database interactions are quick for unpredictable demo environments. Around 10,000 books should be easily manageable, and yet still useful.
Since the file has one book object per line, I can choose any line as the cutoff point without splicing a record, so I went straight for a built-in Linux command called head. The head command prints data starting from the beginning of a file (hence, the term head), and the -n option tells it the number of lines to take. We can then output those to a demo file.
Note: If your data objects are spread over multiple lines, I recommend using something like jq --compact-output to put one record per line. :)
Ok, the main book file was pretty straightforward. With jq to trim out a few larger fields and head to trim down the overall number of data entities, we have a good set of books to load. What about related authors? We would need to select the authors to load based on the ten thousand books we kept in our demo file, right? That calls for some logic.
Here There Be Dragons…
This is where things started to get complicated. We need to take the authors array from the trimmed book file and use that as our source to select only the authors that match and put those in a trimmed author file. That would require some looping and value evaluation. Command line tools like jq do handle some logic and conditional parameters, though I found that commands get complex very quickly.
After spending hours hacking away at options, ordering, and piping, I finally reached out to a colleague or two. The advice I got was that it is probably feasible, but other solutions might be simpler and more efficient. Databases are designed to handle complex data scenarios and splice and dice all day long. Why couldn’t I use a database? Dump data in as-is, select the items I want, then dump that selection back out again.
Because my expertise is in Neo4j (a graph database), this is the solution that resulted:
Import trimmed book file into a free, cloud Neo4j database.
Use a data utility in Neo4j to select the imported books and only import matching authors from the author file.
Write a query to select the imported authors and export them to a demo JSON file.
Use a couple Linux commands to format/clean the data export.
So when do we know when to use what data tool for which job? There doesn’t seem to be much content around this sort of data wrangling, and I now have more than one instance of this frustrating burn of hours to get data cleaned and formatted the way I want for demos. How can I save myself the time and trouble in the future?
I came up with a handy data cleaning decision tree with the hopes of saving myself time and energy! I hope it could do the same for other developers, too.
The Solution: A Decision Tree
First, I put together a decision tree diagram.
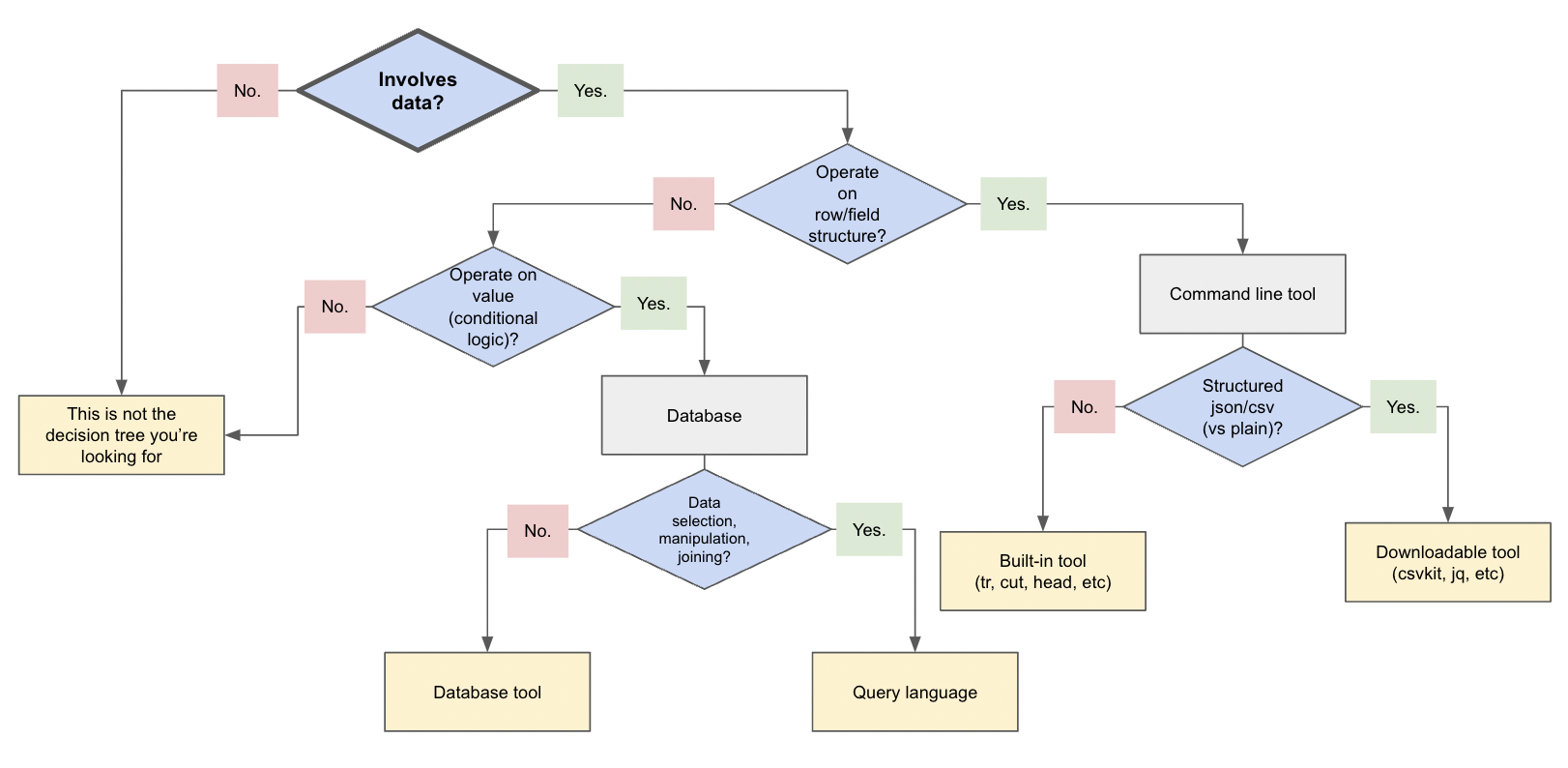
The decision tree focuses on a couple types of operations. I also specifically limited the scope where it only covers those situations. Anything else would need a separate tree.
Let’s talk through a bit of the decisions and why/how they work using our current book JSON data set.
Example: Main book file
The first decision is easy. We are, in fact, working with data, so we can continue to the second decision point. In the case of the main book file, there are a couple of actions we want to take on it.
Remove specific fields by name
Trim the total number of rows in the file
So, either way, we do want to operate on the row and field structures. This takes us to command line tools, where we have a decision on structured versus plain text data format. For this next decision, let’s start with the action to cut specific fields by name. We want to make cuts based on the JSON structure (i.e. field names), so we should use a specifically-designed command line tool (usually requires separate download). There are a variety of these types of tools, depending on the data format. I currently use csvkit for delimited data (CSV, TSV, PSV, etc) and jq for JSON data.
Now let’s go back to our second action on the main book file to cut down the number of rows in the file. Yes, it involves data. Yes, we want to operate on the row.* No, we do not want to make cuts based on the JSON structure itself. This time, we want to arbitrarily trim data based on line numbers. Whether our data is JSON or another format doesn’t matter in this case. This leads us to use a built-in Linux tool like head to slice ten thousand rows from the main file.
*Note: While we do not want to change fields inside the object this time, we want to trim down the overall number of them. I still consider this a row operation, even though it is based on the whole row.
Next, we can take our author file through the paces.
Example: Secondary author file
Previously, this was the piece that caused the most frustration and time lost. Let’s see where this new decision tree takes us! For this file, we want to only select author objects that match the book authors in our smaller book demo file. Therefore…
Yes, our scenario involves data. No, we don’t need to operate on the row/field structure.* Yes, we want to operate on the value with conditional logic (if authors match ones in book file, then keep, otherwise discard).
*Note: Though we do want to evaluate based on the field, we actually are not looking to change the overall structure of the JSON object or the file structure itself. That will stay in tact.
This leads us to use a database, where we then have three steps to get the author data we need.
Import necessary data
Select the subset we want in the resulting file
Export the subset of authors
I used Neo4j graph database as my database choice, although other options work. Neo4j makes several of these steps very easy, but to avoid learning a new database for the sake of some demo data cleaning, I’d recommend you use whatever database you’re comfortable with as a starting point.
Back to our decision tree. Neo4j has a few tools that actually allowed me to combine the "yes" and "no" sides of that final decision, but I recommend putting all your decision logic in a query language. It is what they are designed to do, after all! You can run filtering to gather the authors related to the ten thousand books, then tag those somehow - separate table, new collection, different label, etc. Then, you can use a database tool to dump that segment without additional criteria.
For my Neo4j case, I imported the ten thousand book file to the database, then used a database utility procedure to select those books and only import authors that matched. This means the only authors in my database were the ones I needed. Then, I used a shell tool that ran a query to select those entities, and piped that data to a database utility tool that exported the data to an external file. Because I was using a database export tool, I had to export as plain text, which meant that there was some formatting cleanup to do. Time to consult the decision tree again!
Yes, our situation involves data. Yes, we want to operate on row/field structure. This is due to escape characters (\) before delimeters, so we want to remove those on rows and fields, changing the structure from plain text to standard JSON. This puts us on command line tools, and we are not working with structured data (it is plain text). This means we can use a built-in Linux tool like the tr command to remove the escape character.
Wrapping Up!
The goal for this blog post is to make data set cleaning activities easier and faster by choosing the best tool for the job. Whether you are slicing and dicing structures or selecting and filtering values, each tool comes with its own strengths. Knowing when to switch tools can be a valuable time-saver, allowing us to focus on the use of that data, rather than organizing it.
Hopefully, the decision tree gives us a consistent, repeatable way to avoid getting frustratingly stuck and help us solve problems faster!
Happy coding!
Resources
Example data set: UCSD Book Graph
Command line tool:
jqfor JSON dataCommand line tool:
csvkitfor delimited data (CSV, PSV, TSV, etc)Linux command:
headfor printing data from beginningLinux command:
trfor translating/removing valuesDatabase: Neo4j graph database (free cloud instance)