Agents, Tools, and MCP: A Mental Model That Actually Helps
- 7 minutes read - 1299 wordsEveryone is talking about how magical AI is right now, but if you have spent any time experimenting with it recently, you have probably realized how difficult it is to get the results you want. None of the hype is particularly useful when you are trying to build something real. The magic looks good on paper until it meets real systems.
I recently put together a talk called "Agents, Tools, and MCP, oh my!" that tries to cut through some of that noise. As developers, we are being handed a firehose of new tools and technologies, and I wanted to spend my session doing something a little different: break the pieces apart, reduce some of the complexity and overwhelm, and then build them back up so they actually fit together.
This post is the architecture piece. It lays out the mental model and the "why" behind each layer. If you want to skip ahead, the code is already on GitHub, built with Java, Spring AI, and Neo4j, using a dataset of books, authors, and reviews (because I like to read, and it turns out reading data makes a great demo domain).
How we got here
None of this complexity showed up all at once. A couple of years ago, the foundation of the AI stack was just the large language model, on its own. That was pretty good, until it wasn’t: ask it anything that required knowledge of your users or your data, and it had nothing to work with. So we stacked on vector search and did retrieval augmented generation, also known as naive or easy RAG. That improved things, and then it hit its own wall: retrieval that was too shallow, too literal, missing the relationships between things that actually mattered. So we added filtering and traversals (advanced RAG, GraphRAG) to pull in more precisely related content.
That solved the retrieval problem well enough that a new one became visible: now there were too many pieces to coordinate by hand, so we brought in an agent to sit in the middle and decide what to call and when. Then it turned out the agent had no memory of anything it had already done, so state and history got added on top of that. And once you point any of this at production, you inherit a whole new set of concerns: evals, guardrails, security, all the checks and balances that scale demands.

Every one of those layers was added because the one below it hit a wall. None of this was designed top-down as a system, it was built one patch at a time, in response to the gaps. This means you should evaluate for your own system which layers make the overall solution better and skip those that don’t.
More layers does not mean better
The evaluation of each layer matters because more does not equal better. At some point, your complexity outweighs the value you are getting back from it.
I think about this the same way I think about desserts (I like food). A layered dessert with more textures and flavors is more fun to eat, up to a point. A croissant with more layers of butter and dough is flakier and more interesting, up to a point. But stack too many layers on a dessert and it turns to mush. Stack too many layers of dough on a croissant and the weight collapses the whole thing in the oven before it ever gets to rise.
Tech stacks behave the same way. Somewhere past a certain point, adding another layer stops buying you anything and starts costing you: slower development, harder debugging, more surface area to maintain.
There is no one-size-fits-all stack that solves this for you. What I want to hand you instead is a set of building blocks, so you can decide for yourself, layer by layer, whether your problem actually needs it, rather than reaching for whatever is newest or most talked about.
Four acts, built like a piece of music
I am a musician by background, so I built the talk like a piece of music: four movements, each one earning its place by doing something the last one genuinely could not. That structure turned out to map cleanly onto code, and it is the structure I am using for this whole series.
Act one is a plain LLM, on its own, and it is worth spending real time here because most of us already live in this act without noticing it. Send it a question, get a fluent answer back, right up until the question requires knowing something specific about your users or your data, at which point it either guesses or admits defeat. That gap, between confident reasoning and zero access to anything real, is the entire reason the next three acts exist.
Act two hands the model a way to ask for real data instead of inventing it: structured, typed tool calls instead of a prompt hoping to be obeyed. This is where an agent stops being a buzzword and starts being a reasoning loop you can actually debug: receive input, decide what tool to call, execute it, look at the result, and either answer or loop again.
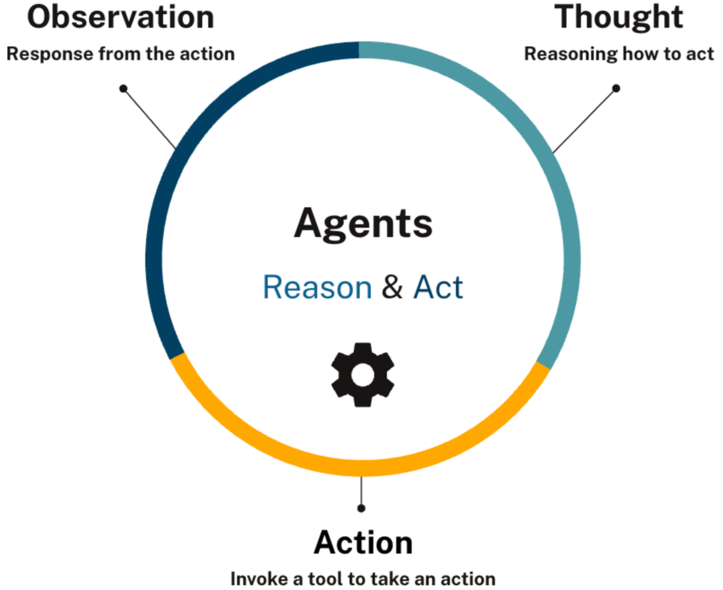
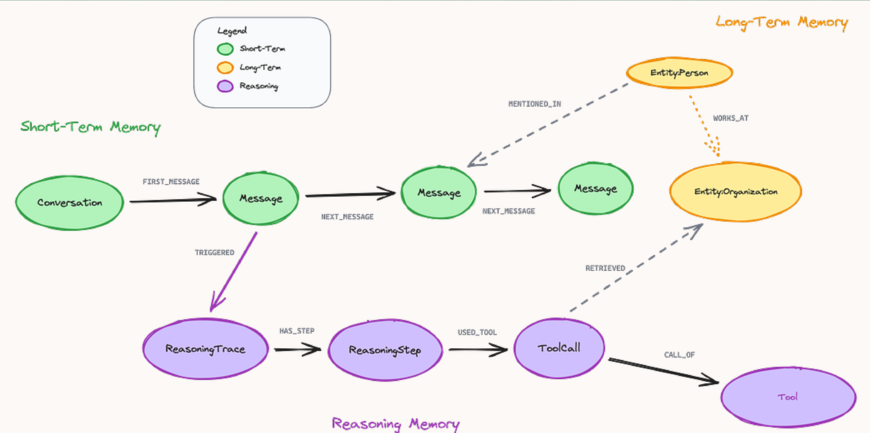
Act three deals with the fact that an LLM forgets everything the moment a request ends. Rather than re-explaining the whole conversation on every turn, memory becomes something the system is responsible for, not the model, and a graph turns out to be a natural place to hold both the short-term thread of a conversation and the long-term knowledge that should persist across many of them.
Act four takes the tools built in act two and pulls them out from underneath the application entirely, using MCP so that a tool definition is not welded to one model, one app, or one team. Swap providers, build a second application, share tools across a team, none of it should require rewriting the integration from scratch, and MCP helps make that happen.
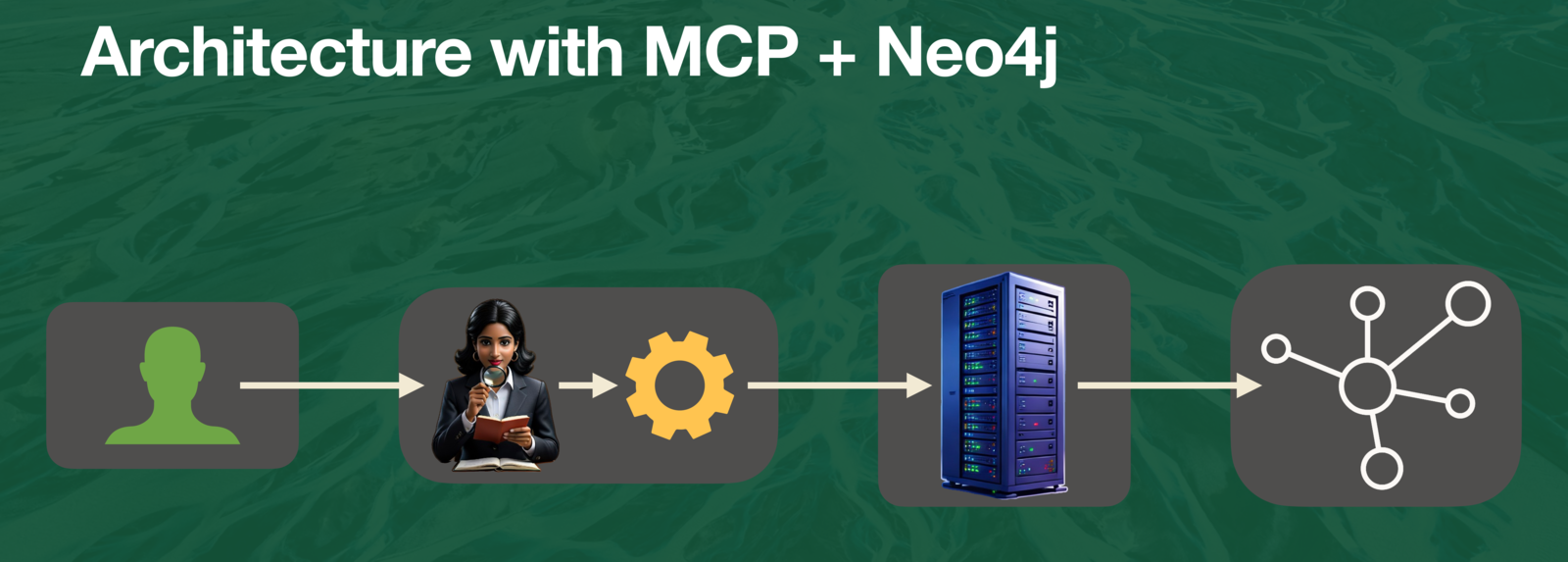
Stepping back, those four acts are really four layers doing four distinct jobs: the LLM reasons, the tools execute, the graph holds context, and MCP standardizes how everything connects. None of that is magic. It is composable architecture, which is genuinely good news, because composable things can be designed, tested, and swapped out independently, and you can actually reason about what broke when something does.
A better question to start with
That reframes the whole problem. "How do we build an AI agent" makes it sound like the agent is the hard part, the thing you optimize. It’s not. The large language model, honestly, is not the most interesting piece of any of this. What matters is everything you build around it: an agent that decides, tools that act, a graph that remembers, a protocol that keeps it all from being welded together.

These are not mysterious, unbuildable things. They are composable layers, and composable layers are something developers already know how to design, test, and put back together differently when the situation calls for it. None of this is magic happening to your application. You are still the one designing the system. The model is just one component inside it.
The next task to build your solution one act at a time and watch where it actually holds up versus where it needs a second look. Act 1 starts with the plain LLM, the same one most of us are already living in without noticing, and shows exactly where it runs out of road.
Happy coding!
Resources
Code repository: Agents, Tools, and MCP demo (Java, Spring AI, Neo4j)
Slide deck: Agents, Tools, and MCP, oh my! (Devnexus 2026)
Course: Context Graphs: Agent Memory with Neo4j (GraphAcademy)
Documentation: Spring AI Tool Calling