Cypher Sleuthing: the EAGER operator
- 7 minutes read - 1428 wordsWhy is it that some query syntax seems to run faster than another when there is very little difference between the statements? Sometimes, queries will invoke what is called the eager operator in order to maintain consistent operations and avoid conflicting data changes.
It still leaves the question, though, of what does this eager operation do differently and why would it be important enough to specifically avoid in certain situations? What are those situations where we would want to choose non-eager and avoid the automatic eager invocation? Let’s take a look!
Cypher Eager
The Cypher documentation actually explains the concept of the eager operator quite well, but I had yet to come across this section until I was doing some research to better understand a user’s question on the topic. Another excellent resource that includes examples is my colleague’s blog post showing how to avoid it in import statements. Using these 2 resources, I constructed some examples to fully understand how this works. We will walk through my test examples in this post to demonstrate.
In short, the eager operator ensures that each operation in a query does not conflict with other operations in the same query. It prevents subsequent operations from altering data from previous operations, maintaining data integrity and intended order of operations. Queries with multiple operations chained together have the potential to write some data in one piece and then read data in the next piece that is out of sync. Eager would ensure that each operation is applied to all rows before moving on to the next query piece to avoid read/write conflicts.
Does it make a difference?
Why does it matter whether Cypher invokes eager or not?
In queries that don’t invoke eager, the executor runs each row to completion before taking in the next row and executing it. It processes the entire query for each row, adds the result to the final output, then takes the next row and executes the entire query on it, adds the result to the final output, and so on. This process is more like a stream and is usually kinder to the heap.
Here it is in logical and visual representations:
Non-eager
Row 1: Operation1, Operation2, Result set = Row1 final
Row 2: Operation1, Operation2, Result set = Row1 final, Row2 final

Eager:
Operation1: Row1, Row2
Operation2: Row1, Row2
Result set = Row1 final, Row2 final
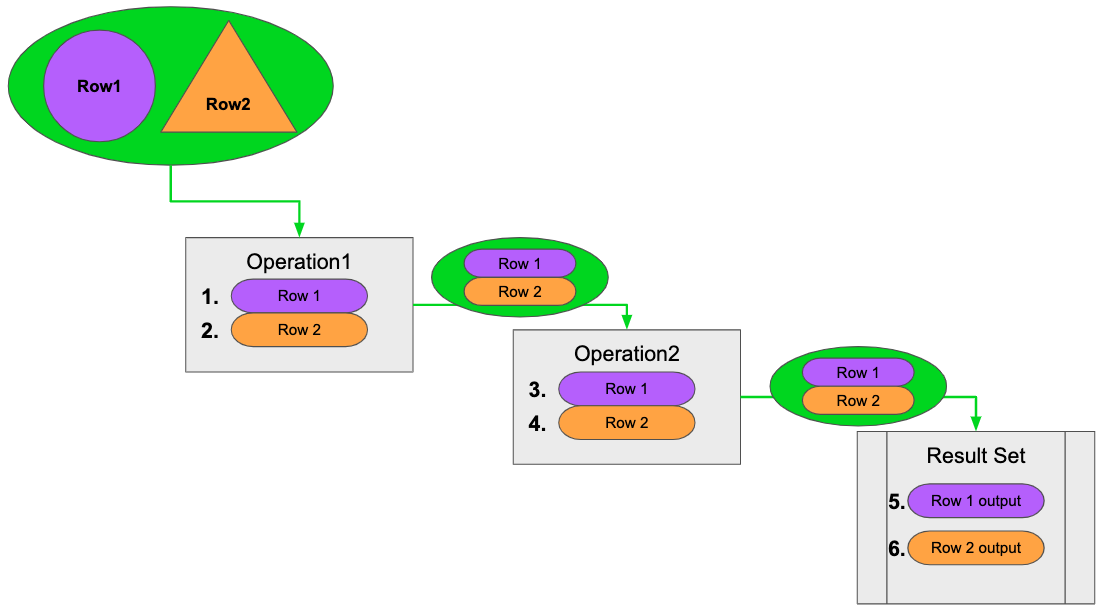
As seen above, when eager is invoked, it instead executes on an operation-to-operation basis. This can put more pressure on the heap because it executes a single operation on all rows before passing all those results to the next operation (which runs on all rows), and so on. The result set cannot begin to compile because all the results are dumped at the end after all operations are completed on all rows.
Eager has been appearing less and less, as our teams find better ways for Cypher to determine conflicting statements and optimize query performance. However, you may occasionally come across this in your queries, and it’s probably avoidable by altering your query syntax or breaking up longer statements into shorter, smaller operations. At the very least, understanding when it appears and what it does can tell you a lot about how Cypher works and why the language operates the way it does.
Simple Example with Eager
Let’s take a silly example to see this in action. We have 5 ids that we want to create as nodes in our graph — 1, 2, 3, 4, 5. Our query will loop through the array and create each node, then add the expected next node.
UNWIND [1,2,3,4,5] as id
MERGE (n:Row {id: id})
MERGE (x:Row {id: n.id + 1})Results from above query:

Because of the two merges with the same label (Row), Cypher avoids a potential conflict by doing the first merge for all the rows first, then doing the second merge. We can see the eager invocation if we put the PROFILE keyword before the above query and execute it.
PROFILE
UNWIND [1,2,3,4,5] as id
MERGE (n:Row {id: id})
MERGE (x:Row {id: id + 1})Running this, you should see output that looks like the below image, where the Eager operation is near the bottom in dark blue:
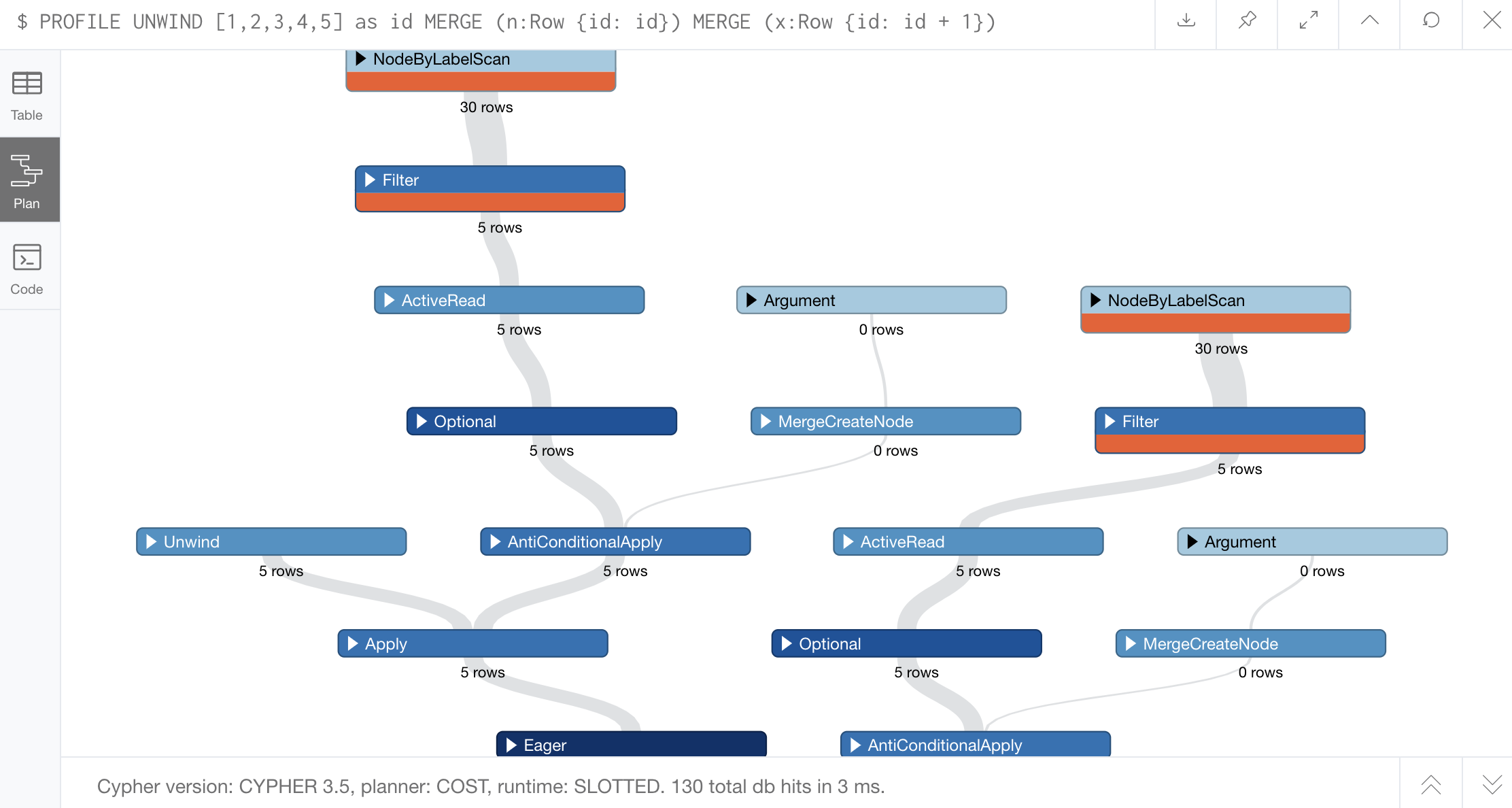
If you notice, there are 2 main funnels that lead to the result. The first funnel is the one coming from the NodeByLabelScan at the top left. That trickles down to the Eager operation we found. The other funnel is one coming from the other NodeByLabelScan on the right. Each one of these funnels is for each of our merge operations. The first merge is creating those 5 nodes (1 for each of the rows we grab from the array) and doing that all at once with eager. The second merge is for creating the expected next node and syncing up with the first merge at the bottom of the funnel.
This is very apparent if you expand each of the NodeByLabelScan operations. The top-left one for the first merge shows (n) in the details. The right one for the second merge shows (x) in the details. These are the node variables used in each of the merge statements from our query above.
Avoiding Eager in our Example
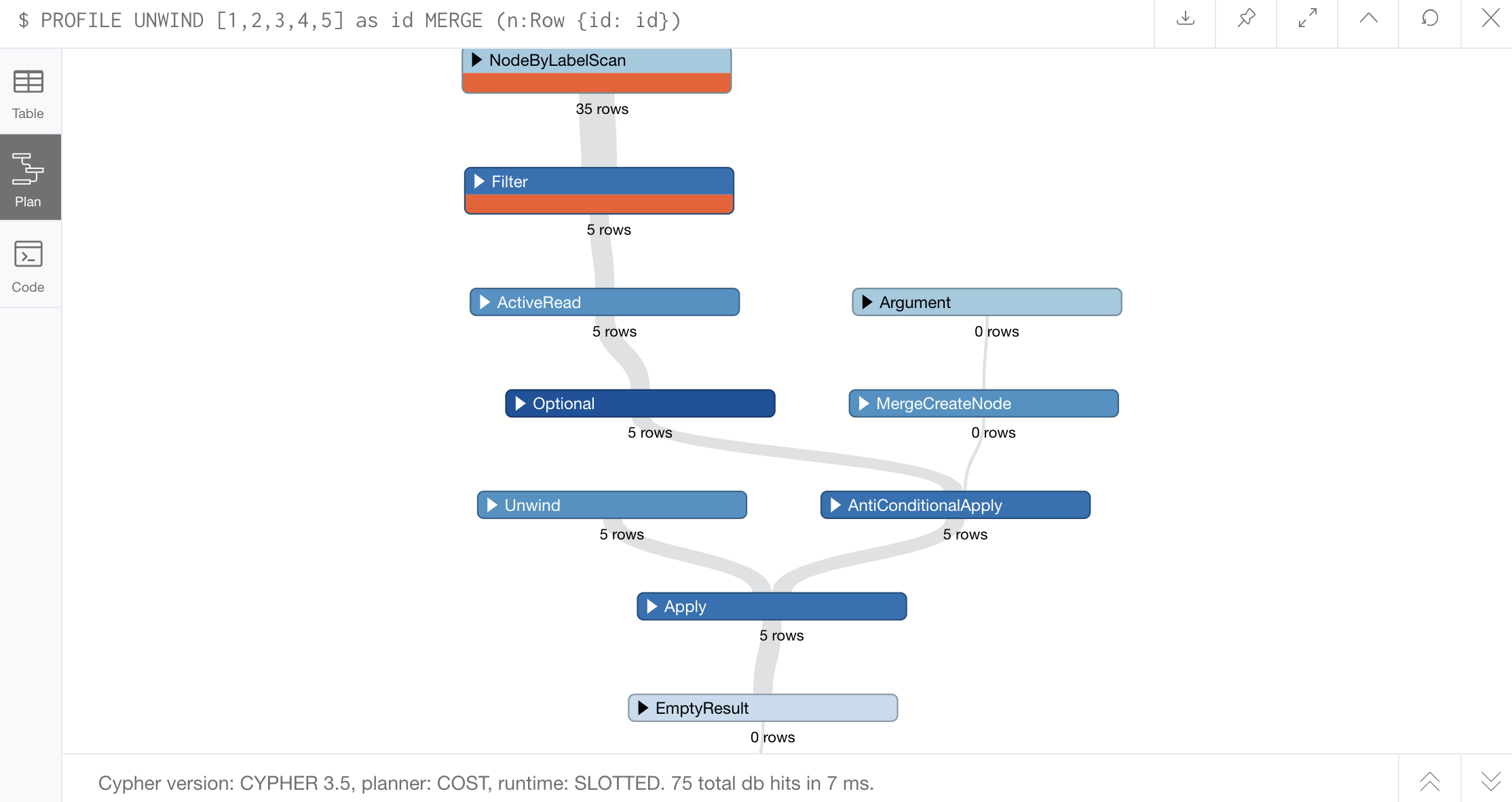
In order to get around the eager operator, we need to ensure Cypher isn’t worried about conflicting operations. The best way to do this is to divide our query into single operations so that Cypher won’t invoke eager as a safeguard. Let’s profile this as two queries to see that.
PROFILE
UNWIND [1,2,3,4,5] as id
MERGE (n:Row {id: id});Results from query above:
PROFILE
UNWIND [1,2,3,4,5] as id
MERGE (x:Row {id: id + 1})Results from query above:
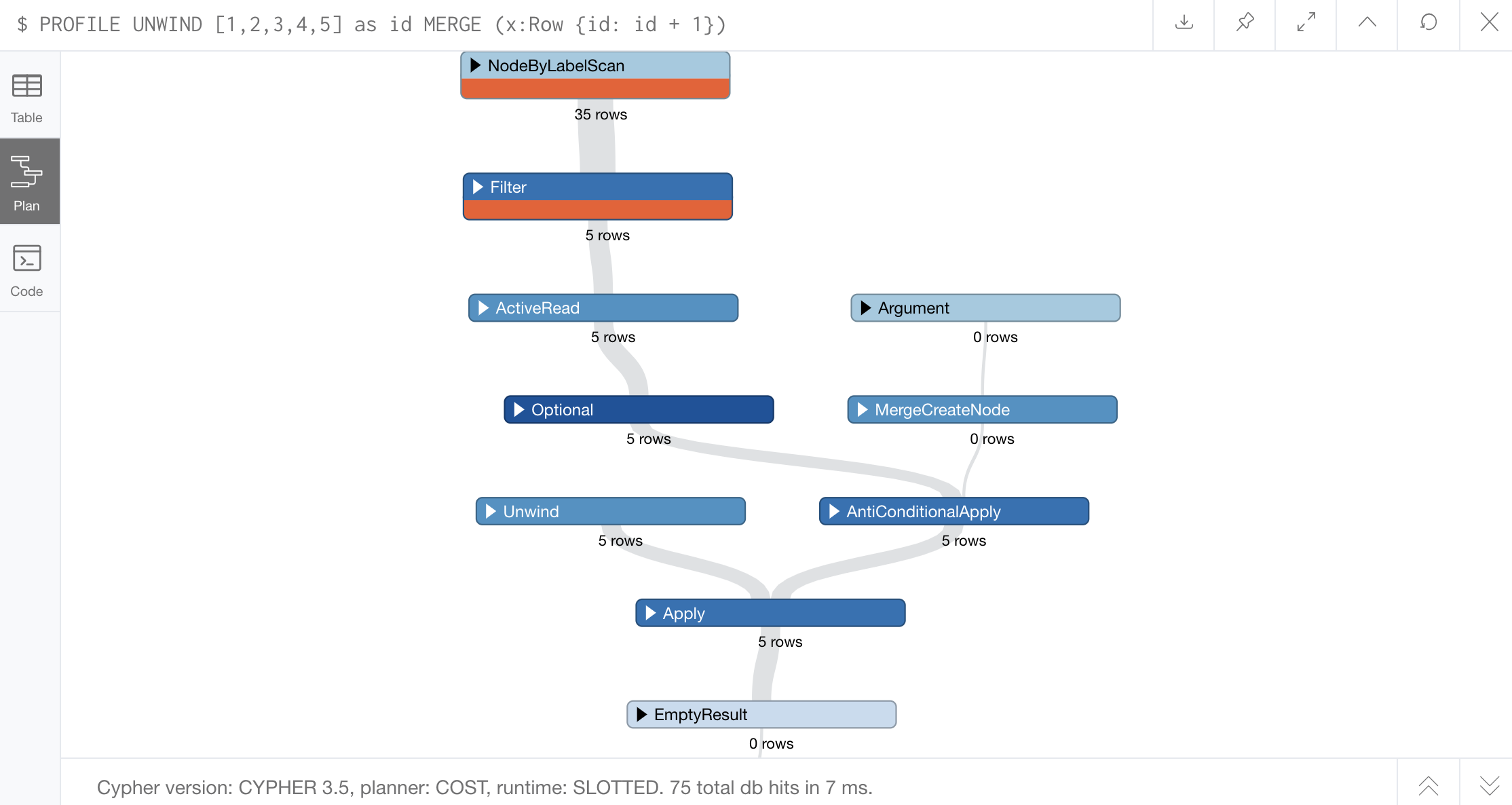
Great! No eager operation visible for either of these.
Another example
Let’s try another example to differentiate and further solidify our knowledge of eager. In this one, we are using our same array ids, but this time we are using them as customer id values and creating related Employee nodes that are assigned to those customers and create the relationship between them.
UNWIND [1,2,3,4,5] as id
MERGE (c:Customer {id: id})
MERGE (e:Employee {id: c.id*10})
MERGE (e)-[r:DEDICATED_TO]->(c);Results from query above:
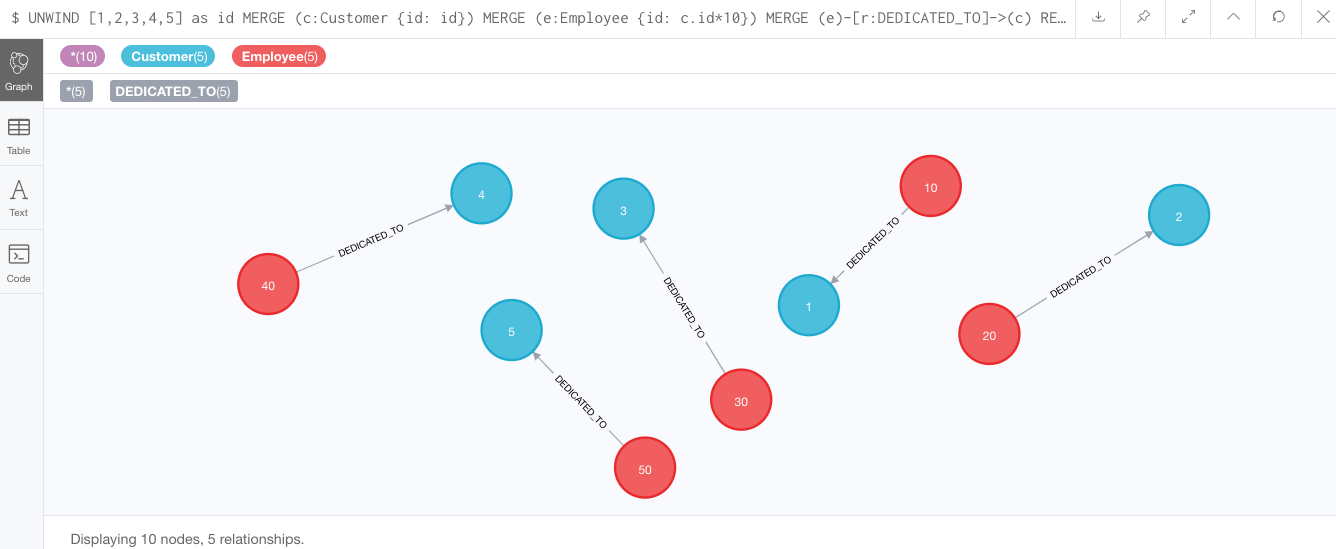
Now, if we run this query with the PROFILE keyword in front of it, we see that Cypher isn’t invoking eager here.
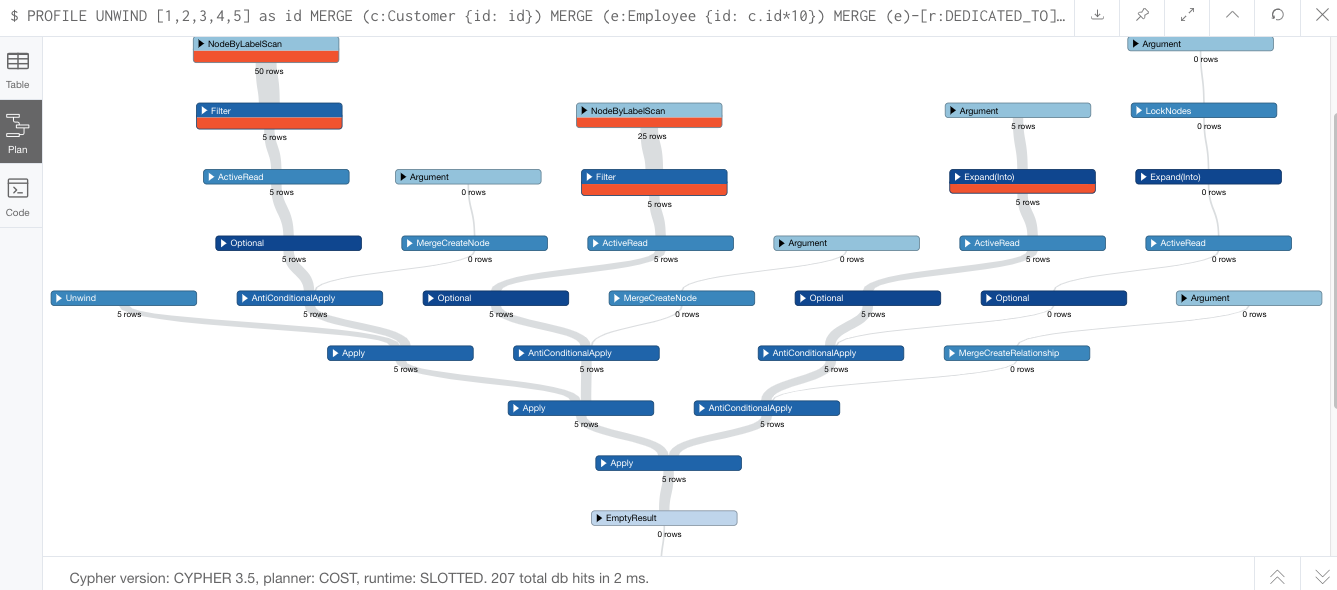
Why is that? Doesn’t the relationship depend on the creation of the nodes? Actually, no, it does not. This is because these writes don’t actually conflict with one another. We are not trying to write and then read the same data again. We are writing 3 separate operations — write Customer node, write Employee node, write Customer/Employee relationship.
We can better see how this works by throwing a read statement in the middle and running PROFILE on that.
PROFILE UNWIND [1,2,3,4,5] as id
MERGE (c:Customer {id: id})
MERGE (e:Employee {id: c.id*10})
WITH c, e, id
MATCH (p:Customer {id: id})
MERGE (e)-[r:DEDICATED_TO]->(c);Results from query above:
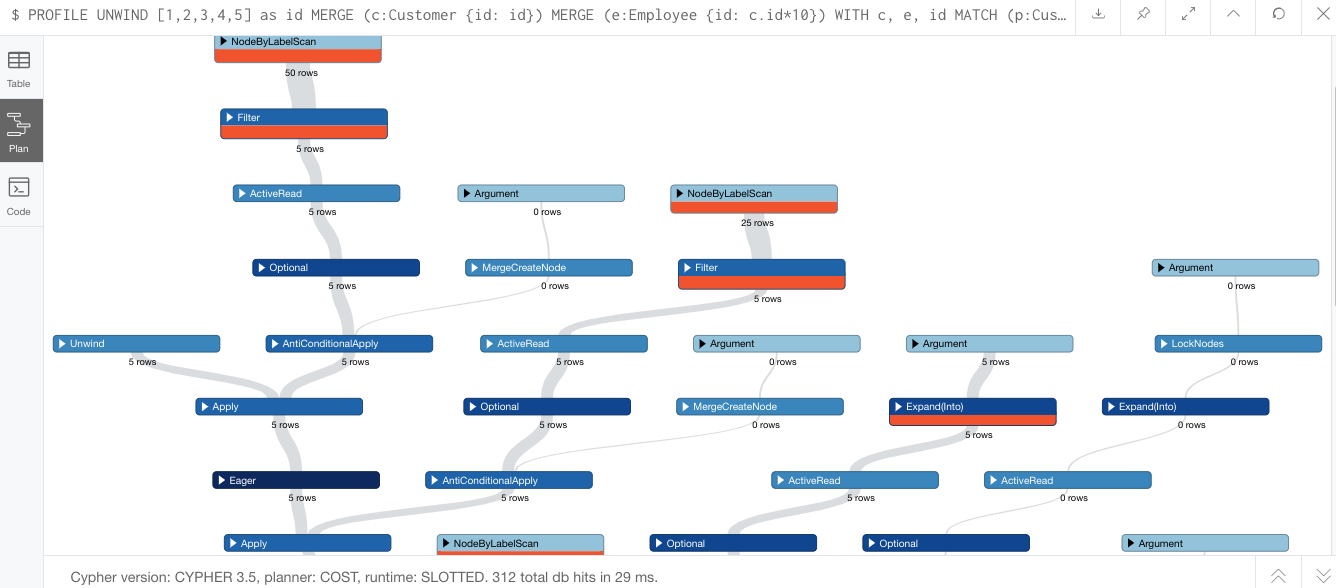
Eager again appears close to the bottom left in dark blue. The only difference between that query and the one we had before is that we’re writing the Customer and Employee nodes, then passing those results to the next operation, which reads a Customer node (simply checking the database for the node we just created) and then using that node to create the relationship. We simply took a query with 3 write operations and turned it into a query with 2 writes, 1 read, and another write.
The read is what invokes the Eager operation because we’re potentially reading the data we just created. Doing the merge, then read, we could potentially have missing results in our read that haven’t been written yet in the 1st write. This is why Cypher does all of the writes first (merge Customer, merge Employee), then it moves on to the read and final write.
Removing that read statement in the middle avoids the eager operator and ensures we don’t have conflicting operations, and we’re back to optimized operations!
Wrap-up
You don’t have to worry about this operator if your data set is small or if your query operations are simple. However, for heavy processing and large datasets, this might be something to check, if your queries are running slowly. When in doubt, break down operations into separate queries where possible and run PROFILE to see what Cypher is doing behind the scenes.
Happy coding!
Resources
Cypher manual: Eager operator
Cypher manual: Eager in execution plans
Blog post: Avoiding the Eager
Query tuning: Profiling your queries
Ask your questions: Neo4j Community Site